我院Roland Eils教授团队在医学顶刊《Nature medicine》发表了关于DeepSeek 开源大语言模型(LLMs)在临床决策中的表现的研究工作!!
近日,由复旦大学智能医学研究院Roland Eils教授团队在医学顶刊《Nature medicine》发表了关于DeepSeek 开源大语言模型(LLMs)在临床决策中的表现的研究工作,并引起了广泛的关注。研究发现,DeepSeek-V3 和 DeepSeek-R1 在诊断和治疗推荐任务上,性能与顶尖专有大语言模型相当,部分情况下甚至更优。

大语言模型在医学领域展现出巨大潜力,可处理复杂医疗信息,辅助临床决策、自动化管理任务并改善患者护理。但专有模型如 GPT-4o 在临床应用中面临障碍,因其无法在医疗机构内部署,难以满足严格的数据隐私法规要求。而开源大语言模型如 DeepSeek 系列,不仅参数规模大,能与专有模型竞争,还具备透明度高、可在机构内部运行且成本低的优势。不过,此前开源模型在临床决策任务中的实际表现缺乏系统评估,此次研究旨在填补这一空白。

科研团队精心挑选 125 个标准化患者病例开展研究,病例涵盖多个医学专科,包括常见疾病和罕见病。他们选用 GPT-4o、Gemini-2.0 Flash Thinking Experimental(Gem2FTE)等专有模型,与 DeepSeek-V3 和 DeepSeek-R1 进行对比。评估过程中,专家依据 5 分李克特量表,手动评估模型生成的文本输出,以确保评估结果的准确性和可靠性。
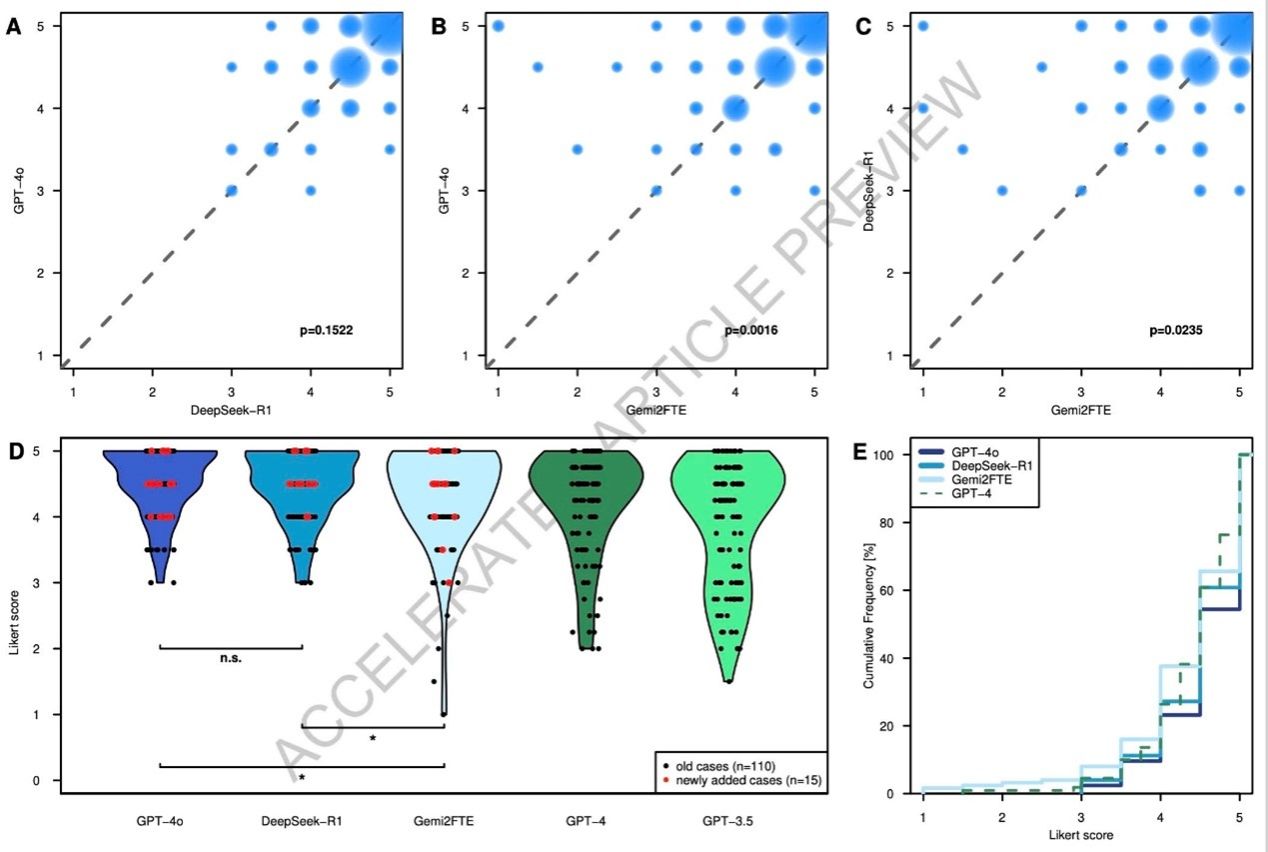
在诊断任务中,研究结果令人惊喜。Gem2FTE表现明显逊于DeepSeek-R1和GPT-4o。DeepSeek-R1则与表现最佳的GPT-4o水平相当,二者无显著差异。值得一提的是,所有新模型在诊断任务上的表现均优于GPT-4、GPT-3.5和谷歌搜索。而且,除Gem2FTE外,其他模型在罕见病诊断方面与常见疾病诊断表现相近,这与此前对GPT-4、GPT-3.5和谷歌搜索的研究结果形成鲜明对比。

治疗推荐任务的评估结果同样出色。GPT-4o和DeepSeek-R1的表现均优于Gem2FTE,且二者之间无显著差异。相较于之前研究中的GPT-4、GPT-3.5和DeepSeek-R1也展现出明显优势,而Gem2FTE则未体现优势。疾病发病率对模型治疗推荐性能的影响较小,且多数模型在各临床专科的表现较为一致。
尽管DeepSeek系列模型表现优异,但研究也指出其存在的不足。部分病例中,模型预测结果未未达满分,若模型输出在无专家审核的情况下直接用于医疗决策,可能存在风险。“人工幻觉”现象虽在所有模型中出现频率较低,但也不容忽视。

此次研究表明开源大语言模型在临床决策支持任务中表现良好,是医疗领域有价值的辅助工具,为医疗机构提供了更安全、经济且合规的选择。随着医院对数据隐私和法规合规性的重视,开源大语言模型可在机构内部进行安全、低成本的训练和应用,为医疗行业带来新的发展方向。
不过,要将这些研究成果转化为实际临床应用,仍面临诸多挑战。未来,需建立更强大的验证框架和明确的指南,确保大语言模型在临床使用中的安全性和有效性。同时,可通过接入经过质量检验的医学文献和数据库、引入人工审核以及采用更透明的学习方法等方式,进一步提升模型性能,后续还需开展更多临床研究,评估这些模型对患者治疗效果的实际影响。




